|
I am a Member of Technical Staff at cohere where I work on post-training. Previously I was a Sr Machine Learning Scientist at Layer6 where I mainly worked on foundation models for tabular data and time series. I previously graduated from my PhD at Mila, where I worked on Reinforcement Learning and Deep Learning under supervision of Yoshua Bengio and Nicolas Le Roux. Email / CV / Google Scholar / Twitter / Github |

|
|
I'm interested in reinforcement learning, deep learning and optimization. I have worked on unsupervised RL, planning, generalization in deep learning and optimization aspects of reinforcement learning. Representative papers are highlighted. Stars * indicate first authorship. |
|
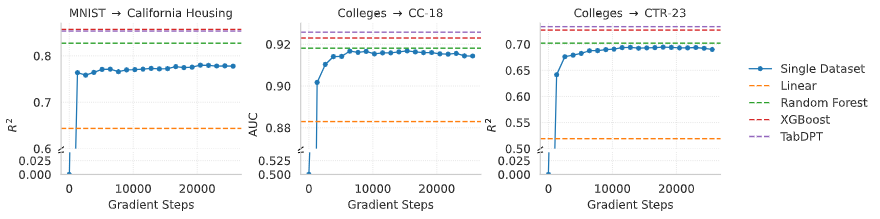
Junwei Ma, Nour Shaheen, Alex Labach, Amine Mhedhbi, Frank Hutter, Anthony L. Caterini, Valentin Thomas We show that ICL can generalize to many tables and modalities even when training on only one limited data source! We investigate this phenomenon and find it is deeply connected to the number of tasks one can create from even limited data. |
|
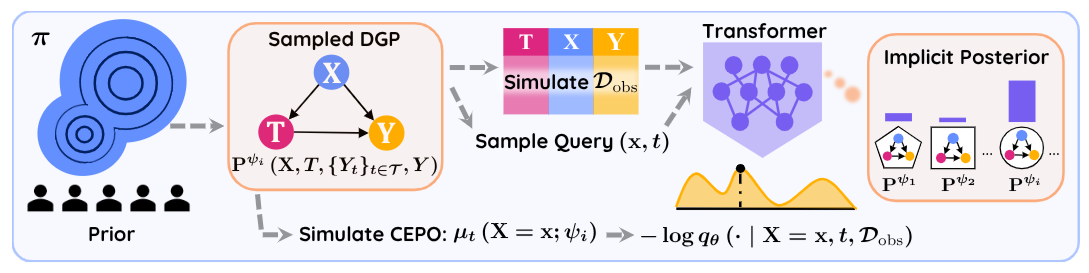
Vahid Balazadeh*, Hamidreza Kamkari*, Valentin Thomas, Benson Li, Junwei Ma, Jesse C. Cresswell, Rahul G. Krishnan We show how to train an In-Context tabular foundation model to enable causal effect estimation. I was involved in pretraining a suitable base model for this task. Congratulations to Vahid and Hamid for the causal post-training and theory! |
|
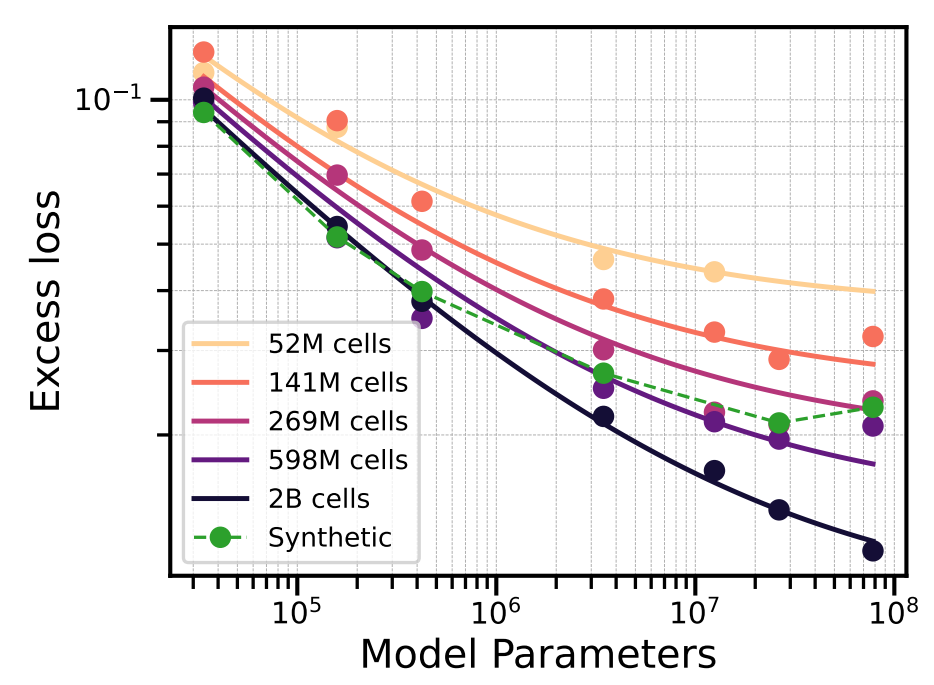
Valentin Thomas*, Junwei Ma*, Rasa Hosseinzadeh, Hamidreza Kamkari, Alex Labach, Jesse C. Cresswell, Keyvan Golestan, Guangwei Yu, Maksims Volkovs, Anthony Caterini We introduce TabDPT, a tabular foundation model capable of providing predictions for unseen tabular datasets with no further training or hyperparameter tuning, and demonstrate scaling in both model and dataset size. |
|
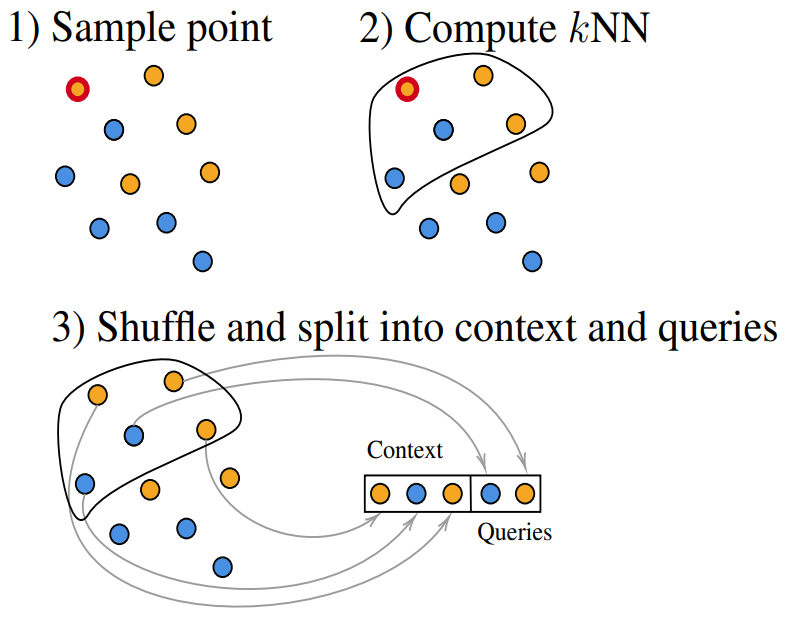
Valentin Thomas*, Junwei Ma*, Rasa Hosseinzadeh, Keyvan Golestan, Guangwei Yu, Maksims Volkovs, Anthony Caterini We use retrieval with fine-tuning to improve in-context learning on tabular data and show large improvement with better scaling. |
|
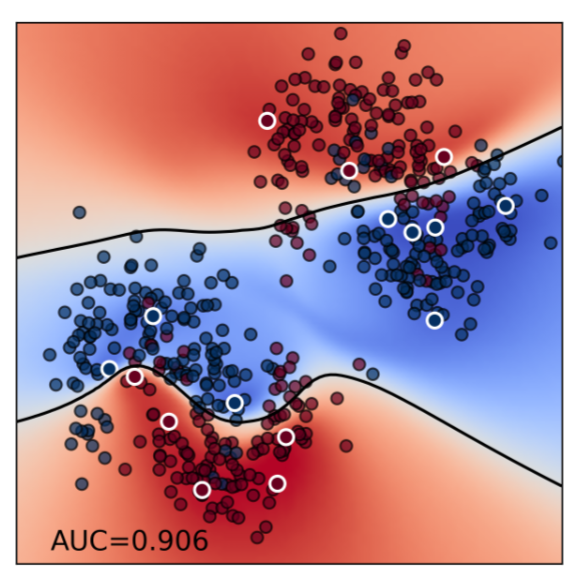
Junwei Ma, Valentin Thomas, Guangwei Yu, Anthony Caterini We propose a simple method similar to prompt tuning to allow in-context foundation tabular models to scale efficient with the dataset size. |
|
Alexandre Piché*, Valentin Thomas*, Joseph Marino, Rafael Pardinas, Gian Maria Marconi, Christopher Pal, Mohammad Emtiyaz Khan We analyze the implicit regularization performed by using Target Networks and show that, surprisingly, it can unstabilize TD. We propose a theoretically grounded alternative method, Functional Regularization, which alleviates these theoretical issues and performs well empirically. |
|
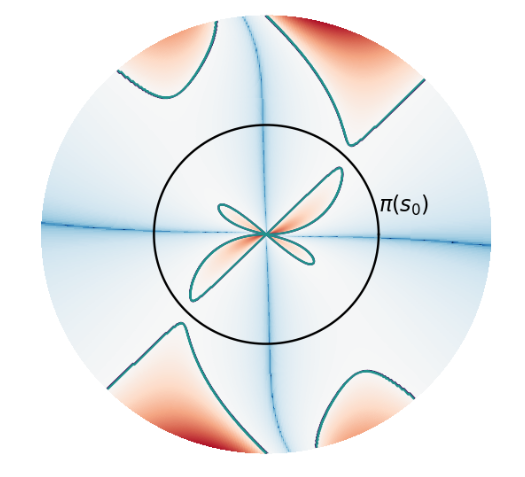
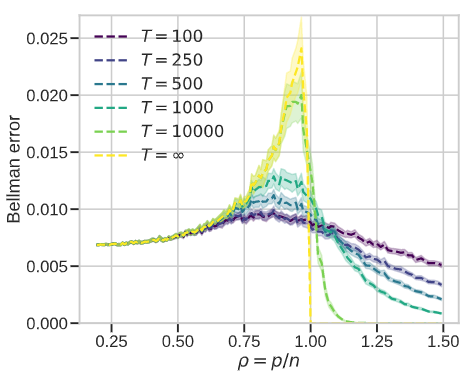
Valentin Thomas* We study the role of overparameterization in Temporal Difference (TD) learning and how it affects optimization. For this, we analyze the spectrum of the Temporal Difference operator when using random features and with some assumptions of the Markov transition kernel. |
|
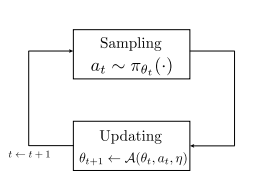
Jincheng Mei*, Wesley Chung, Valentin Thomas, Bo Dai, Csaba Szepesvari, Dale Schuurmans Using value function baselines in on-policy stochastic natural policy gradients help achieve convergence toward globally optimal policy by reducing update aggressiveness rather than variance. |
|
Valentin Thomas*, Wesley Chung*, Marlos C. Machado, Nicolas Le Roux blog post/ICML talk We show empirically and theoretically that despite common wisdom, baselines in policy gradient optimization have an effect beyond variance reduction and can impact convergence. |
|
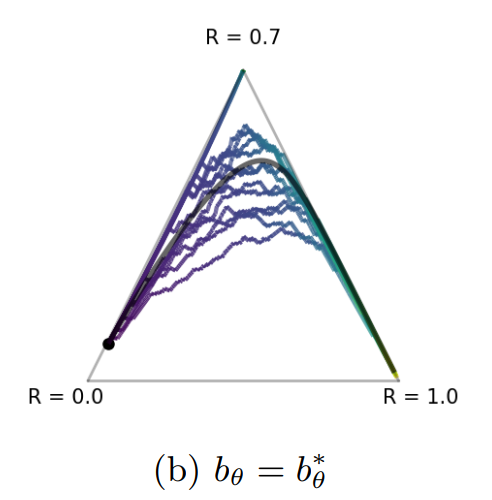
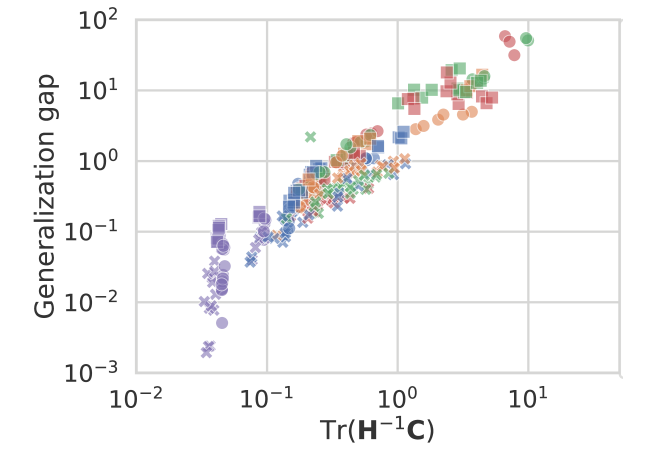
Valentin Thomas*, Fabian Pedregosa, Bart van Merriënboer, Pierre-Antoine Mangazol, Yoshua Bengio, Nicolas Le Roux AISTATS talk We show how the interplay between the local curvature of the loss (the hessian) and the local gradient noise (the uncentered gradient covariance) can impact optimization and generalization in neural networks. |
|
Alexandre Piché, Valentin Thomas, Cyril Ibrahim, Yoshua Bengio, Julien Cornebise and Chris Pal Extension of our work "Probabilistic Planning with Sequential Monte Carlo methods" by treating the trajectory as a latent variable and using an EM algorithm. |
|
Valentin Thomas*, Alexandre Piché*, Cyril Ibrahim, Yoshua Bengio and Chris Pal Leveraging control as inference and Sequential Monte Carlo methods, we propose a probabilistic planning algorithm. |
|
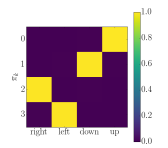
Valentin Thomas*, Emmanuel Bengio*, William Fedus*, Jules Pondard, Philippe Beaudoin, Hugo Larochelle, Joelle Pineau, Doina Precup and Yoshua Bengio We draw a connection between mutual information and the intrinsic reward function (through the Donsker-Varadhan representation of the Kullback-Leibler divergence) used for learning jointly options/factors and latent representations in Independently Controllable Factors. |
|
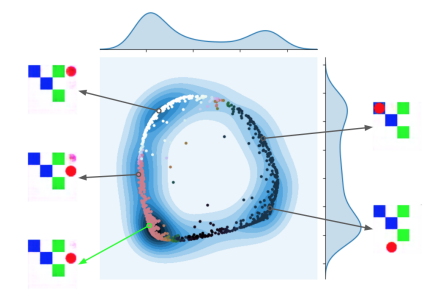
Valentin Thomas*, Jules Pondard*, Emmanuel Bengio*, Marc Sarfati, Philippe Beaudoin, Marie-Jean Meurs, Joelle Pineau, Doina Precup, Yoshua Bengio This work is a finalized version of Independently Controllable Features where the policies and factors are now embedded in a contiuous space. We demonstrate how one can use the features learnt. |
|
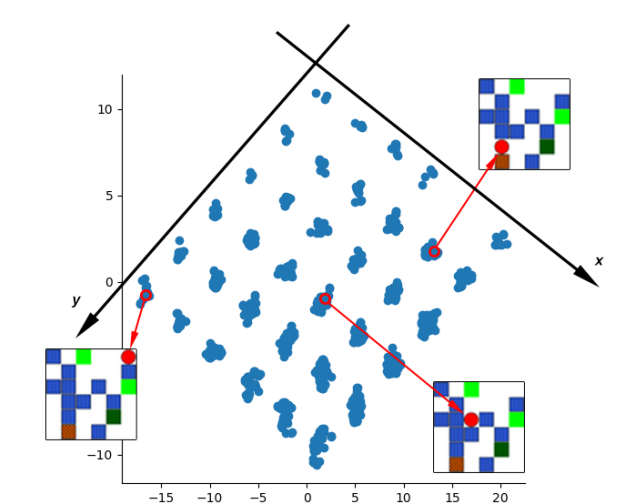
Emmanuel Bengio*, Valentin Thomas, Joelle Pineau, Doina Precup, Yoshua Bengio We propose a way to learn jointly a set of discrete policies each affecting a component of the latent state representation for unsupervised reinforcement learning. We hypothesize that this process discovers controllable factors of variation in the world as well as how to control them. |
|
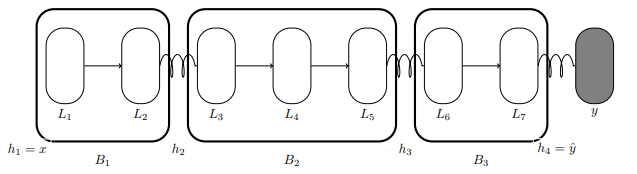
Valentin Thomas*, Akhilesh Gotmare*, Johanni Brea and Martin Jaggi We propose BlockProp which lets one train deep neural networks in model parallel fashion, where parts of the model may reside on different devices (GPUs). |
|
Valentin Thomas*, Pierre Rouchon Report for a research semester in 2014 (in french) This research project was about designing a feeback control loop using an electromagnetic field to preserve the entanglement of two qbits. This is necessary as because of quantum decoherence the entanglement tends to vanish which is a major issue in developping quantum computer hardware. We proposed a simple Lyapunov-based feedback control loop. |
|
Website template from Jon Barron (source code). |